Latte: Latent Diffusion Transformer for Video Generation
Abstract: We propose Latte, a novel Latent Diffusion Transformer for video generation. Latte first extracts spatio-temporal tokens from input videos and then adopts a series of Transformer blocks to model video distribution in the latent space. In order to model a substantial number of tokens extracted from videos, four efficient variants are introduced from the perspective of decomposing the spatial and temporal dimensions of input videos. To improve the quality of generated videos, we determine the best practices of Latte through rigorous experimental analysis, including video clip patch embedding, model variants, timestep-class information injection, temporal positional embedding, and learning strategies. Our comprehensive evaluation demonstrates that Latte achieves state-of-the-art performance across four standard video generation datasets, i.e., FaceForensics, SkyTimelapse, UCF101, and Taichi-HD. In addition, we extend Latte to the text-to-video generation (T2V) task, where Latte achieves results that are competitive with recent T2V models. We strongly believe that Latte provides valuable insights for future research on incorporating Transformers into diffusion models for video generation.
- Bao F, Nie S, Xue K, et al (2023) All are worth words: A vit backbone for diffusion models. In: Computer Vision and Pattern Recognition, pp 22669–22679 Blattmann et al [2023a] Blattmann A, Dockhorn T, Kulal S, et al (2023a) Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:231115127 Blattmann et al [2023b] Blattmann A, Rombach R, Ling H, et al (2023b) Align your latents: High-resolution video synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 22563–22575 Chen et al [2023a] Chen J, Yu J, Ge C, et al (2023a) Pixart-α𝛼\alphaitalic_α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. arXiv preprint arXiv:231000426 Chen et al [2020] Chen M, Radford A, Child R, et al (2020) Generative pretraining from pixels. In: International Conference on Machine Learning, PMLR, pp 1691–1703 Chen et al [2023b] Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Blattmann A, Dockhorn T, Kulal S, et al (2023a) Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:231115127 Blattmann et al [2023b] Blattmann A, Rombach R, Ling H, et al (2023b) Align your latents: High-resolution video synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 22563–22575 Chen et al [2023a] Chen J, Yu J, Ge C, et al (2023a) Pixart-α𝛼\alphaitalic_α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. arXiv preprint arXiv:231000426 Chen et al [2020] Chen M, Radford A, Child R, et al (2020) Generative pretraining from pixels. In: International Conference on Machine Learning, PMLR, pp 1691–1703 Chen et al [2023b] Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Blattmann A, Rombach R, Ling H, et al (2023b) Align your latents: High-resolution video synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 22563–22575 Chen et al [2023a] Chen J, Yu J, Ge C, et al (2023a) Pixart-α𝛼\alphaitalic_α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. arXiv preprint arXiv:231000426 Chen et al [2020] Chen M, Radford A, Child R, et al (2020) Generative pretraining from pixels. In: International Conference on Machine Learning, PMLR, pp 1691–1703 Chen et al [2023b] Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Chen J, Yu J, Ge C, et al (2023a) Pixart-α𝛼\alphaitalic_α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. arXiv preprint arXiv:231000426 Chen et al [2020] Chen M, Radford A, Child R, et al (2020) Generative pretraining from pixels. In: International Conference on Machine Learning, PMLR, pp 1691–1703 Chen et al [2023b] Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Chen M, Radford A, Child R, et al (2020) Generative pretraining from pixels. In: International Conference on Machine Learning, PMLR, pp 1691–1703 Chen et al [2023b] Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Blattmann A, Dockhorn T, Kulal S, et al (2023a) Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:231115127 Blattmann et al [2023b] Blattmann A, Rombach R, Ling H, et al (2023b) Align your latents: High-resolution video synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 22563–22575 Chen et al [2023a] Chen J, Yu J, Ge C, et al (2023a) Pixart-α𝛼\alphaitalic_α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. arXiv preprint arXiv:231000426 Chen et al [2020] Chen M, Radford A, Child R, et al (2020) Generative pretraining from pixels. In: International Conference on Machine Learning, PMLR, pp 1691–1703 Chen et al [2023b] Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Blattmann A, Rombach R, Ling H, et al (2023b) Align your latents: High-resolution video synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 22563–22575 Chen et al [2023a] Chen J, Yu J, Ge C, et al (2023a) Pixart-α𝛼\alphaitalic_α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. arXiv preprint arXiv:231000426 Chen et al [2020] Chen M, Radford A, Child R, et al (2020) Generative pretraining from pixels. In: International Conference on Machine Learning, PMLR, pp 1691–1703 Chen et al [2023b] Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Chen J, Yu J, Ge C, et al (2023a) Pixart-α𝛼\alphaitalic_α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. arXiv preprint arXiv:231000426 Chen et al [2020] Chen M, Radford A, Child R, et al (2020) Generative pretraining from pixels. In: International Conference on Machine Learning, PMLR, pp 1691–1703 Chen et al [2023b] Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Chen M, Radford A, Child R, et al (2020) Generative pretraining from pixels. In: International Conference on Machine Learning, PMLR, pp 1691–1703 Chen et al [2023b] Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Blattmann A, Rombach R, Ling H, et al (2023b) Align your latents: High-resolution video synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 22563–22575 Chen et al [2023a] Chen J, Yu J, Ge C, et al (2023a) Pixart-α𝛼\alphaitalic_α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. arXiv preprint arXiv:231000426 Chen et al [2020] Chen M, Radford A, Child R, et al (2020) Generative pretraining from pixels. In: International Conference on Machine Learning, PMLR, pp 1691–1703 Chen et al [2023b] Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Chen J, Yu J, Ge C, et al (2023a) Pixart-α𝛼\alphaitalic_α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. arXiv preprint arXiv:231000426 Chen et al [2020] Chen M, Radford A, Child R, et al (2020) Generative pretraining from pixels. In: International Conference on Machine Learning, PMLR, pp 1691–1703 Chen et al [2023b] Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Chen M, Radford A, Child R, et al (2020) Generative pretraining from pixels. In: International Conference on Machine Learning, PMLR, pp 1691–1703 Chen et al [2023b] Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Chen J, Yu J, Ge C, et al (2023a) Pixart-α𝛼\alphaitalic_α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. arXiv preprint arXiv:231000426 Chen et al [2020] Chen M, Radford A, Child R, et al (2020) Generative pretraining from pixels. In: International Conference on Machine Learning, PMLR, pp 1691–1703 Chen et al [2023b] Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Chen M, Radford A, Child R, et al (2020) Generative pretraining from pixels. In: International Conference on Machine Learning, PMLR, pp 1691–1703 Chen et al [2023b] Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Chen M, Radford A, Child R, et al (2020) Generative pretraining from pixels. In: International Conference on Machine Learning, PMLR, pp 1691–1703 Chen et al [2023b] Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Chen R, Chen Y, Jiao N, et al (2023b) Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: International Conference on Computer Vision Chen et al [2023c] Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Chen X, Wang Y, Zhang L, et al (2023c) Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint arXiv:231020700 Deng et al [2009] Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recognition, IEEE, pp 248–255 Devlin et al [2019] Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics : Human Language Technologies Dhariwal and Nichol [2021] Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Dhariwal P, Nichol A (2021) Diffusion models beat gans on image synthesis. Neural Information Processing Systems 34:8780–8794 Dosovitskiy et al [2021] Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations Ge et al [2022] Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Ge S, Hayes T, Yang H, et al (2022) Long video generation with time-agnostic vqgan and time-sensitive transformer. In: European Conference on Computer Vision, Springer, pp 102–118 Harvey et al [2022] Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Harvey W, Naderiparizi S, Masrani V, et al (2022) Flexible diffusion modeling of long videos. Neural Information Processing Systems 35:27953–27965 He et al [2016] He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp 770–778 He et al [2023] He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- He Y, Yang T, Zhang Y, et al (2023) Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:221113221 Ho et al [2020] Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. Neural Information Processing Systems 33:6840–6851 Ho et al [2022] Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Ho J, Salimans T, Gritsenko A, et al (2022) Video diffusion models. In: Neural Information Processing Systems Huang et al [2017] Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Huang H, He R, Sun Z, et al (2017) Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In: International Conference on Computer Vision, pp 1689–1697 Jia et al [2021] Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Jia G, Zheng M, Hu C, et al (2021) Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science 3(3):308–319 Jia et al [2022] Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Jia G, Huang H, Fu C, et al (2022) Rethinking image cropping: Exploring diverse compositions from global views. In: Computer Vision and Pattern Recognition, pp 2446–2455 Kahembwe and Ramamoorthy [2020] Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Kahembwe E, Ramamoorthy S (2020) Lower dimensional kernels for video discriminators. Neural Networks 132:506–520 Kaplan et al [2020] Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Kaplan J, McCandlish S, Henighan T, et al (2020) Scaling laws for neural language models. arXiv preprint arXiv:200108361 Lu et al [2023] Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Lu H, Yang G, Fei N, et al (2023) Vdt: General-purpose video diffusion transformers via mask modeling. arXiv preprint arXiv:230513311 Luo et al [2021a] Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Luo M, Cao J, Ma X, et al (2021a) Fa-gan: Face augmentation gan for deformation-invariant face recognition. IEEE Transactions on Information Forensics and Security 16:2341–2355 Luo et al [2021b] Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Luo M, Ma X, Li Z, et al (2021b) Partial nir-vis heterogeneous face recognition with automatic saliency search. IEEE Transactions on Information Forensics and Security 16:5003–5017 Luo et al [2022] Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Luo M, Ma X, Huang H, et al (2022) Style-based attentive network for real-world face hallucination. In: Pattern Recognition and Computer Vision, Springer, pp 262–273 Luo et al [2023] Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Luo Z, Chen D, Zhang Y, et al (2023) Videofusion: Decomposed diffusion models for high-quality video generation. In: Computer Vision and Pattern Recognition Ma et al [2021] Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Ma X, Zhou X, Huang H, et al (2021) Free-form image inpainting via contrastive attention network. In: International Conference on Pattern Recognition, IEEE, pp 9242–9249 Ma et al [2022] Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Ma X, Zhou X, Huang H, et al (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recognition 124:108465 Ma et al [2023] Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Ma X, Zhou X, Huang H, et al (2023) Uncertainty-aware image inpainting with adaptive feedback network. Expert Systems with Applications p 121148 Mei and Patel [2023] Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Mei K, Patel V (2023) Vidm: Video implicit diffusion models. In: AAAI Conference on Artificial Intelligence, pp 9117–9125 Meng et al [2022] Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Meng C, He Y, Song Y, et al (2022) Sdedit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations Neimark et al [2021] Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Neimark D, Bar O, Zohar M, et al (2021) Video transformer network. In: International Conference on Computer Vision, pp 3163–3172 Nichol and Dhariwal [2021] Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Nichol AQ, Dhariwal P (2021) Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning, PMLR, pp 8162–8171 Parmar et al [2021] Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Parmar G, Zhang R, Zhu JY (2021) On buggy resizing libraries and surprising subtleties in fid calculation. arXiv preprint arXiv:210411222 5:14 Parmar et al [2023] Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Parmar G, Kumar Singh K, Zhang R, et al (2023) Zero-shot image-to-image translation. In: ACM SIGGRAPH Conference, pp 1–11 Parmar et al [2018] Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Parmar N, Vaswani A, Uszkoreit J, et al (2018) Image transformer. In: International Conference on Machine Learning, PMLR, pp 4055–4064 Peebles and Xie [2023] Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Peebles W, Xie S (2023) Scalable diffusion models with transformers. In: International Conference on Computer Vision, pp 4195–4205 Perez et al [2018] Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Perez E, Strub F, De Vries H, et al (2018) Film: Visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Antelligence Pota et al [2020] Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Pota M, Esposito M, De Pietro G, et al (2020) Best practices of convolutional neural networks for question classification. Applied Sciences 10(14):4710 Rakhimov et al [2021] Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Rakhimov R, Volkhonskiy D, Artemov A, et al (2021) Latent video transformer. In: Computer Vision, Imaging and Computer Graphics Theory and Applications Ramesh et al [2022] Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Ramesh A, Dhariwal P, Nichol A, et al (2022) Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:220406125 1(2):3 Rombach et al [2022] Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Rombach R, Blattmann A, Lorenz D, et al (2022) High-resolution image synthesis with latent diffusion models. In: Computer Vision and Pattern Recognition, pp 10684–10695 Ronneberger et al [2015] Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention, Springer, pp 234–241 Rössler et al [2018] Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Rössler A, Cozzolino D, Verdoliva L, et al (2018) Faceforensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:180309179 Ruiz et al [2023] Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Ruiz N, Li Y, Jampani V, et al (2023) Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Computer Vision and Pattern Recognition, pp 22500–22510 Saharia et al [2022a] Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Saharia C, Chan W, Chang H, et al (2022a) Palette: Image-to-image diffusion models. In: ACM SIGGRAPH Conference, pp 1–10 Saharia et al [2022b] Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Saharia C, Chan W, Saxena S, et al (2022b) Photorealistic text-to-image diffusion models with deep language understanding. Neural Information Processing Systems 35:36479–36494 Saito et al [2017] Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Saito M, Matsumoto E, Saito S (2017) Temporal generative adversarial nets with singular value clipping. In: International Conference on Computer Vision, pp 2830–2839 Shen et al [2023] Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Shen X, Li X, Elhoseiny M (2023) Mostgan-v: Video generation with temporal motion styles. In: Computer Vision and Pattern Recognition, pp 5652–5661 Shue et al [2023] Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Shue JR, Chan ER, Po R, et al (2023) 3d neural field generation using triplane diffusion. In: Computer Vision and Pattern Recognition, pp 20875–20886 Siarohin et al [2019] Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Siarohin A, Lathuilière S, Tulyakov S, et al (2019) First order motion model for image animation. Neural Information Processing Systems 32 Simonyan and Zisserman [2014] Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. Neural Information Processing Systems 27 Singer et al [2022] Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Singer U, Polyak A, Hayes T, et al (2022) Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:220914792 Skorokhodov et al [2022] Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Skorokhodov I, Tulyakov S, Elhoseiny M (2022) Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In: Computer Vision and Pattern Recognition, pp 3626–3636 Song et al [2021a] Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Song J, Meng C, Ermon S (2021a) Denoising diffusion implicit models. In: International Conference on Learning Representations Song et al [2021b] Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Song Y, Sohl-Dickstein J, Kingma DP, et al (2021b) Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations Soomro et al [2012] Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Soomro K, Zamir AR, Shah M (2012) A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision 2(11) Su et al [2021] Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Su J, Lu Y, Pan S, et al (2021) Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864 Tian et al [2021] Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Tian Y, Ren J, Chai M, et al (2021) A good image generator is what you need for high-resolution video synthesis. In: International Conference on Learning Representations Tulyakov et al [2018] Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Tulyakov S, Liu MY, Yang X, et al (2018) Mocogan: Decomposing motion and content for video generation. In: Computer Vision and Pattern Recognition, pp 1526–1535 Unterthiner et al [2018] Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Unterthiner T, Van Steenkiste S, Kurach K, et al (2018) Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:181201717 Vaswani et al [2017] Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Neural Information Processing Systems 30 Vondrick et al [2016] Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Vondrick C, Pirsiavash H, Torralba A (2016) Generating videos with scene dynamics. Neural Information Processing Systems 29 Wang et al [2023a] Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Wang H, Du X, Li J, et al (2023a) Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Computer Vision and Pattern Recognition, pp 12619–12629 Wang et al [2020a] Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Wang Y, Bilinski P, Bremond F, et al (2020a) G3an: Disentangling appearance and motion for video generation. In: Computer Vision and Pattern Recognition, pp 5264–5273 Wang et al [2020b] Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Wang Y, Bilinski P, Bremond F, et al (2020b) Imaginator: Conditional spatio-temporal gan for video generation. In: Winter Conference on Applications of Computer Vision Wang et al [2023b] Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Wang Y, Chen X, Ma X, et al (2023b) Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:230915103 Wang et al [2023c] Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Wang Y, Ma X, Chen X, et al (2023c) Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:230503989 Weissenborn et al [2020] Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Weissenborn D, Täckström O, Uszkoreit J (2020) Scaling autoregressive video models. In: International Conference on Learning Representations Xiong et al [2018] Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Xiong W, Luo W, Ma L, et al (2018) Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks. In: Computer Vision and Pattern Recognition, pp 2364–2373 Yan et al [2021] Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Yan W, Zhang Y, Abbeel P, et al (2021) Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:210410157 Yu et al [2022] Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Yu S, Tack J, Mo S, et al (2022) Generating videos with dynamics-aware implicit generative adversarial networks. In: International Conference on Learning Representations Yu et al [2023] Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Yu S, Sohn K, Kim S, et al (2023) Video probabilistic diffusion models in projected latent space. In: Computer Vision and Pattern Recognition, pp 18456–18466 Zhang et al [2023] Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Zhang L, Rao A, Agrawala M (2023) Adding conditional control to text-to-image diffusion models. In: International Conference on Computer Vision, pp 3836–3847 Zhao et al [2022] Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Zhao M, Bao F, Li C, et al (2022) Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Neural Information Processing Systems 35:3609–3623 Zhou et al [2021] Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Zhou L, Du Y, Wu J (2021) 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision, pp 5826–5835 Zhou et al [2022] Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Zhou Y, Zhang R, Chen C, et al (2022) Towards language-free training for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 17907–17917 Zhou et al [2023] Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166 Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
- Zhou Y, Liu B, Zhu Y, et al (2023) Shifted diffusion for text-to-image generation. In: Computer Vision and Pattern Recognition, pp 10157–10166
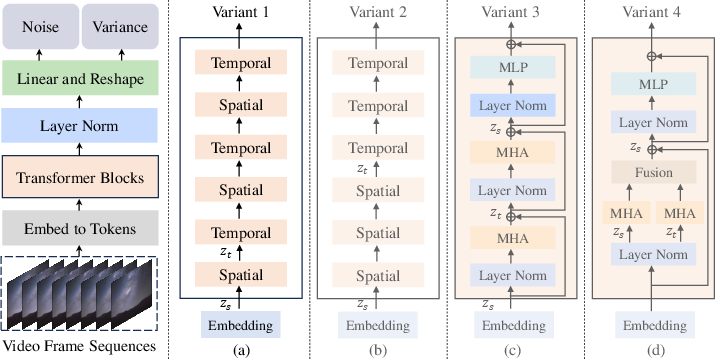
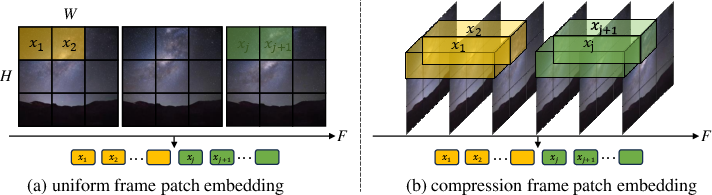
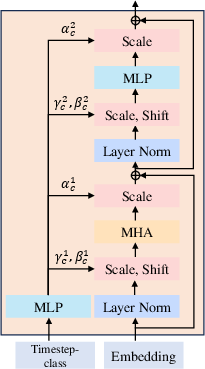
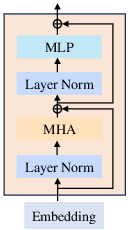
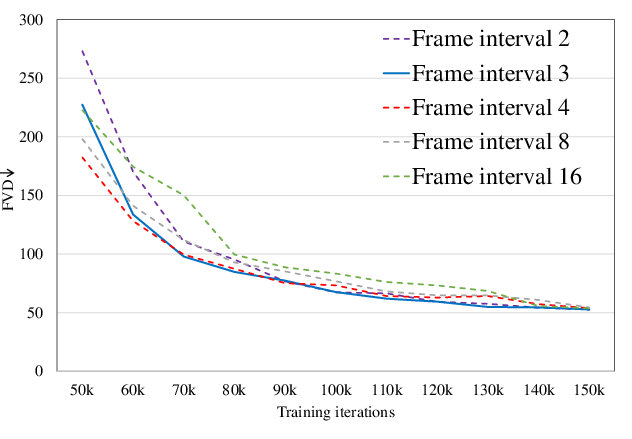
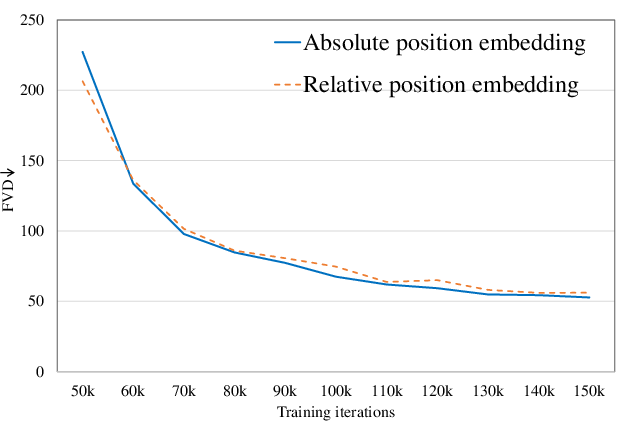
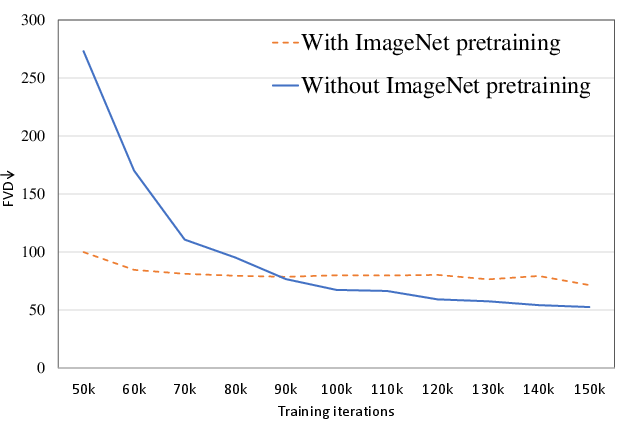
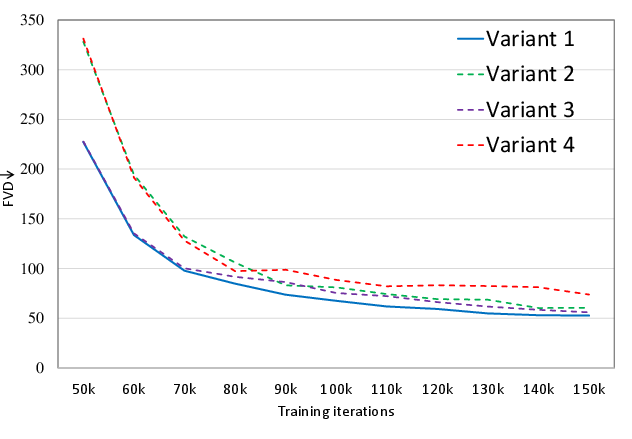
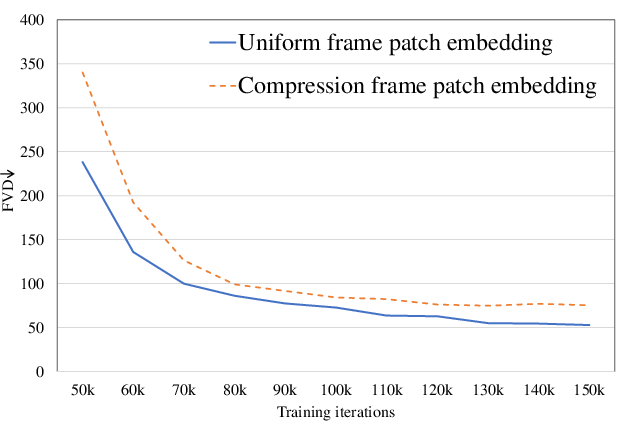
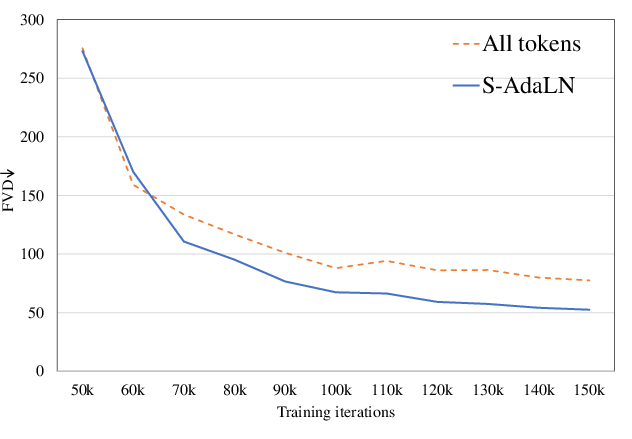


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

